OCR是Optical Character Recognition的缩写,即光学字符识别。它是一种将纸质文档、票据、表格等转换为电子文本的技术。 OCR技术可以通过对图像文件进行分析识别处理,获取文字及版面信息的过程,即将图像中的文字进行识别,并以文本的形式返回。 简单来说就是可以把图片上的内容识别成文本。 在我们日常个工作中可能偶尔会需要用到类似的工具
一般来说我们会随机找个在线的OCR识别工具站来使用,当然如果是深度用户的话,可能想在电脑上拥有自己的客户端OCR程序。那么今天我就来分享一款开源好用的OCR软件。Umi-OCR ,它的github地址如下:https://github.com/hiroi-sora/Umi-OCR 在github上拥有12.3K star。
简单介绍一下umiOCR,他它可以将图片转文字识别软件,完全离线。截屏/批量导入图片,支持多国语言、合并段落、竖排文字。可排除水印区域,提取干净的文本。基于 PaddleOCR 。作者目前已经更新的工作放在了v2上,所以我们今天就来介绍 umiOCR 的后续版本:https://github.com/hiroi-sora/Umi-OCR_v2/releases
umiOCR v2的特性如下

那么接下来我们就下载来看看效果。下载的时候会有2个版本供我们选择一个是Paddle 引擎插件版,这个版本性能好,速度快,占用率高,适合高配机器,一个是Rapid 引擎插件版,速度稍慢,内存占用低,兼容好,适合低配机器。当然windows7以上的电脑都可以装,使用过程也无需联网!
打开之后页面展示如下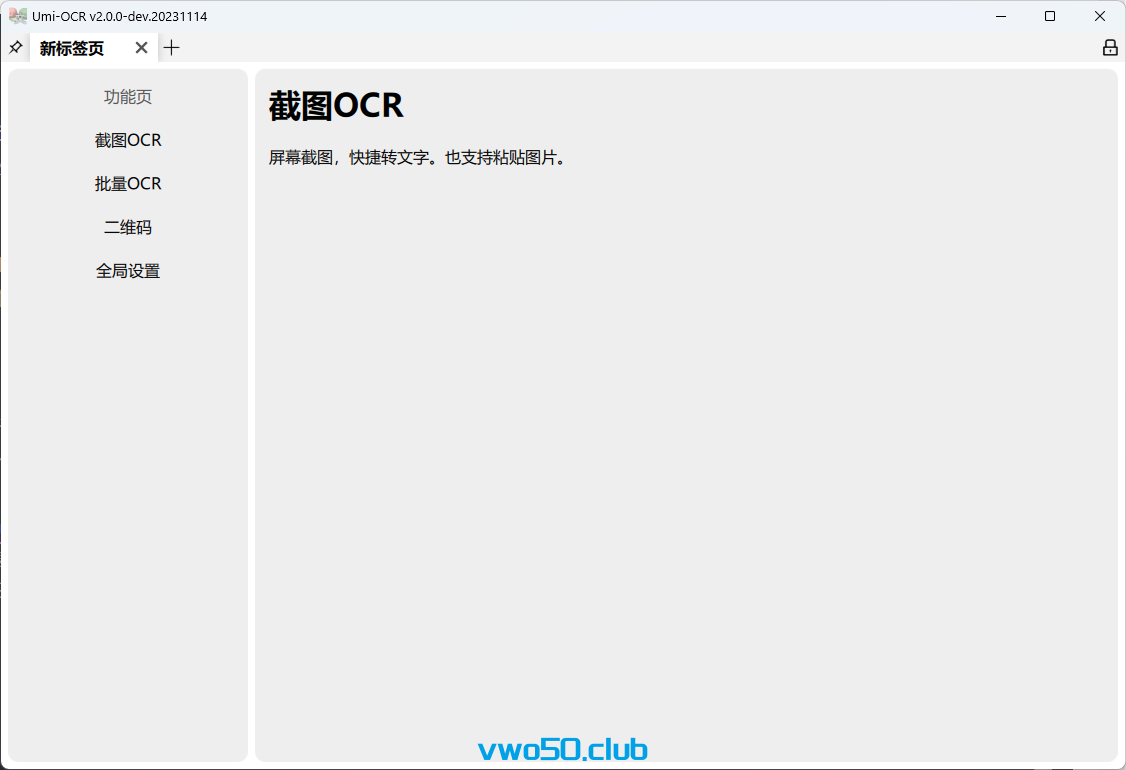
- 我们先看它的第一个功能,截图OCR,我就不多赘述了,大家直接看效果。

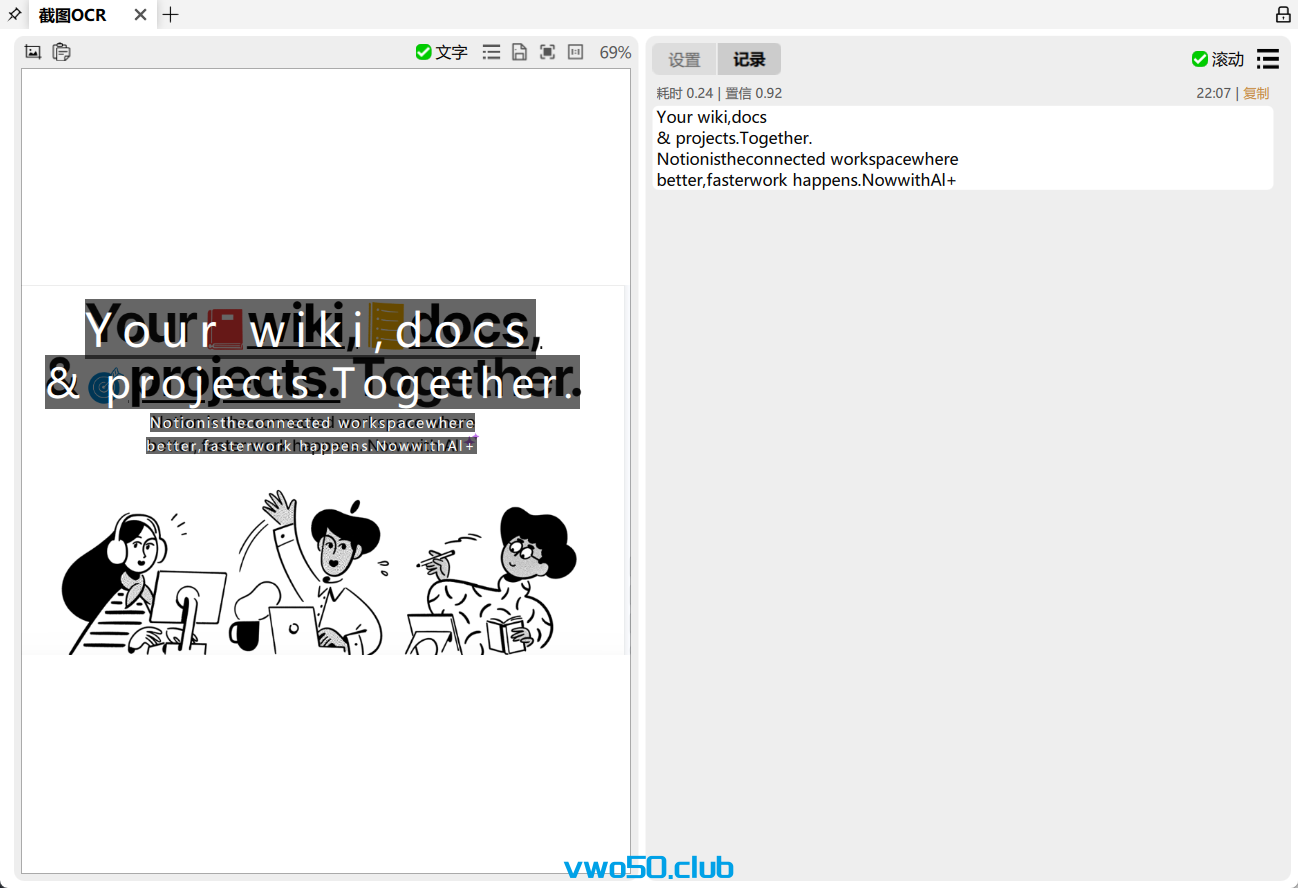
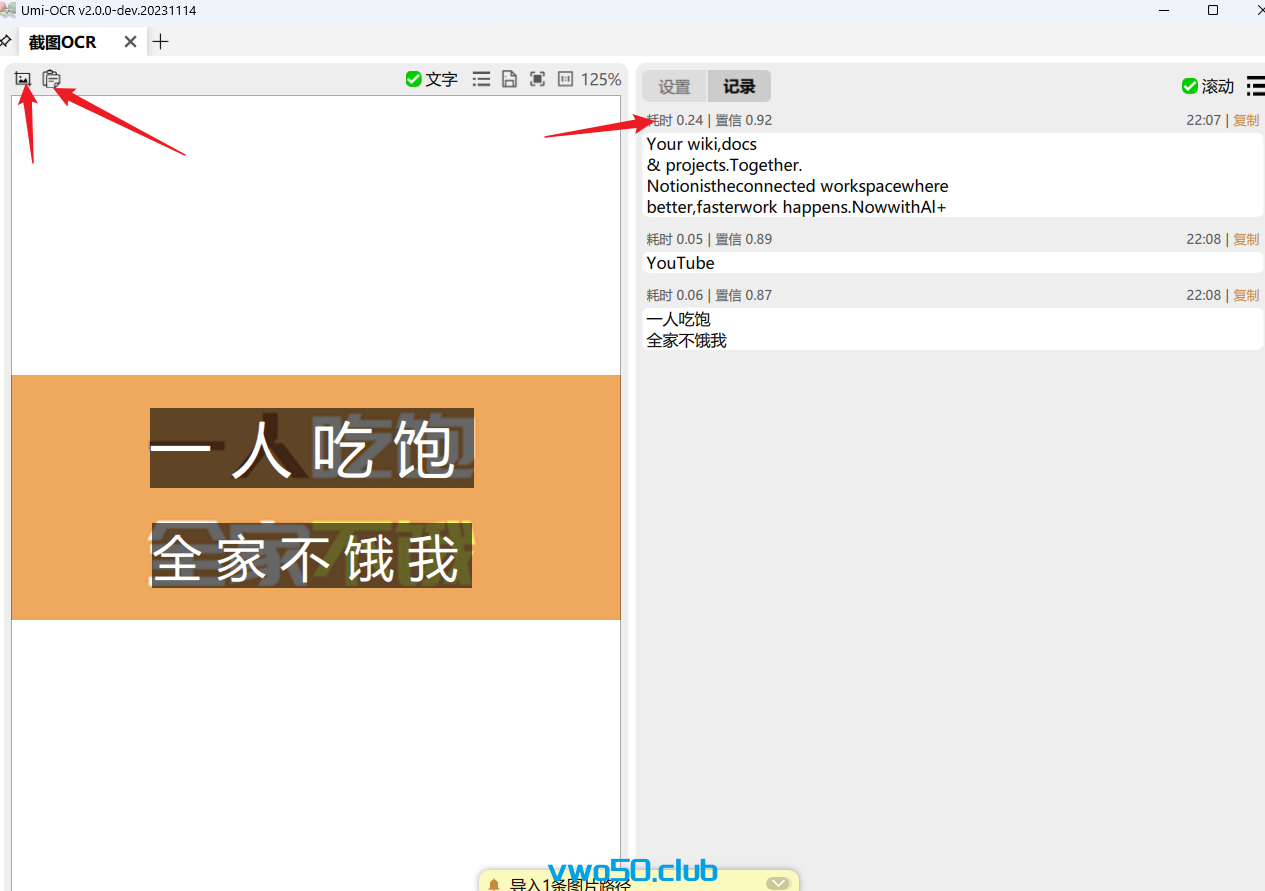 速度快的令人发指。 你可以正常选中图片拖到这个页面里面进行识别,也可以点击第一个按钮,直接进入截图模式,截完图之后会自动OCR识别。 也可以复制图片之后,点击第二个按钮,直接读取复制内容图片进行OCR识别。
速度快的令人发指。 你可以正常选中图片拖到这个页面里面进行识别,也可以点击第一个按钮,直接进入截图模式,截完图之后会自动OCR识别。 也可以复制图片之后,点击第二个按钮,直接读取复制内容图片进行OCR识别。 - 第二个功能,批量OCR:
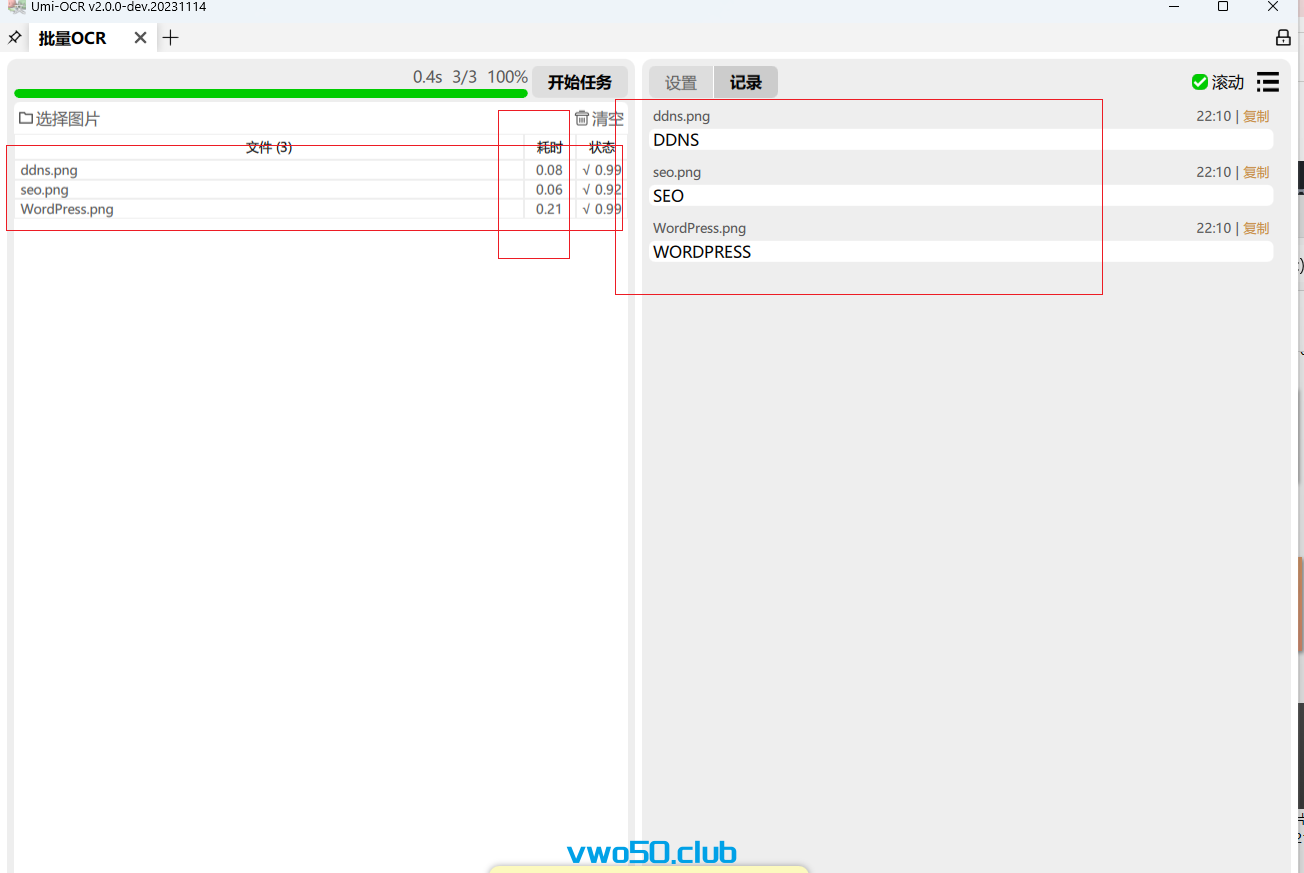 。我将我文章素材的3张图片直接选中,选中之后点击开始任务。就可以将对应图片的识别结果分别列出,速度也是一如既往的快!
。我将我文章素材的3张图片直接选中,选中之后点击开始任务。就可以将对应图片的识别结果分别列出,速度也是一如既往的快! - 其他比如是识别和生成二维码功能,全局设置,这几个功能就不再演示了,大家可以自行探索。
总体用下来体验非常好!值得推荐,如果要下载的话可能要连接github,下载会比较慢,所以我直接将下载地址放到博客里。可以访问 https://vwo50.club/archives/1139.html 来获取下载地址
创作不易,如果您觉得这篇文章对你有帮助,不妨给我点个赞,这将是我继续分享优质内容的动力。
